Latest essays on AI safety explorations
This article aims to provide an overview of compute governance and the framework designed by Yonadav Shavit (2023).
July 23, 2024

This article aims to provide an overview of compute governance and the framework designed by Yonadav Shavit (2023) [1]. The authors are not experts in the topic and do not claim to be. Reading into the topic and writing this blogpost was done within 7 hours.
The fast-paced development of Machine Learning (ML) systems has been an impressive feat to witness during the past few years. In the figure below, you can see the timeline for various deployed models as a function of the number of floating point operations (FLOP) required to train them. With increasing compute and other improvements, state-of-the-art models have achieved impressive capabilities that can be employed in a variety of tasks and environments. The practical uses of these models are increasing and it is becoming more and more pressing to develop regulations and measures regarding their deployment and their use.
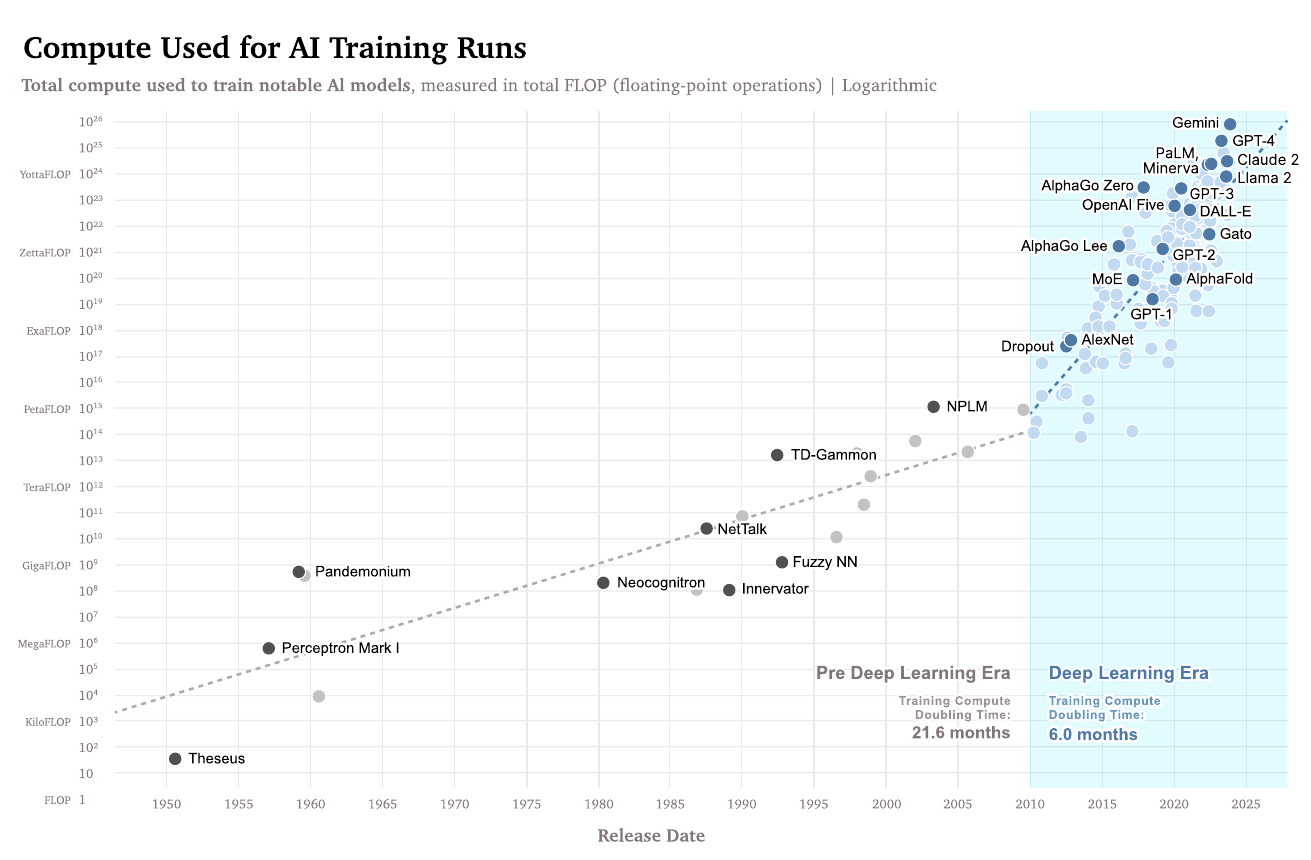
Fig 1: The importance of compute AI in a historical context. [3]
The nascent field of AI governance is tackling this task. In this article, we aim to give an overview of AI compute governance in particular. Recent legislative initiatives have begun to address this area, notably the CHIPS and Science Act in the United States, which aims to bolster domestic semiconductor manufacturing and research and counter China. Additionally, both the European Union and United States have proposed AI acts that incorporate specific computational thresholds for data centres, measured in FLOP. These legislative measures represent initial attempts to quantify and regulate the computational resources utilised in AI development, reflecting the growing recognition of compute as a key factor in AI capabilities and potential risks.
Compute governance can be defined as the control and management of access to compute resources. It stands out as a very impactful approach to governance with a big potential for proposing concrete measures due to the nature of compute hardware [3]:
In 2023, Yonadav Shavit proposed the Chinchilla framework, aimed at enabling governments or international organisations to monitor and verify AI companies' compliance with regulations while preserving the privacy of sophisticated ML models and avoiding interference with consumer computing devices.
Key components of the framework [1]
This framework has the goal to allow a verifier (e.g. a government) to check if a prover (e.g. an AI lab) complies with the existing legislation on AI safety. It (see figure below) includes three main steps:
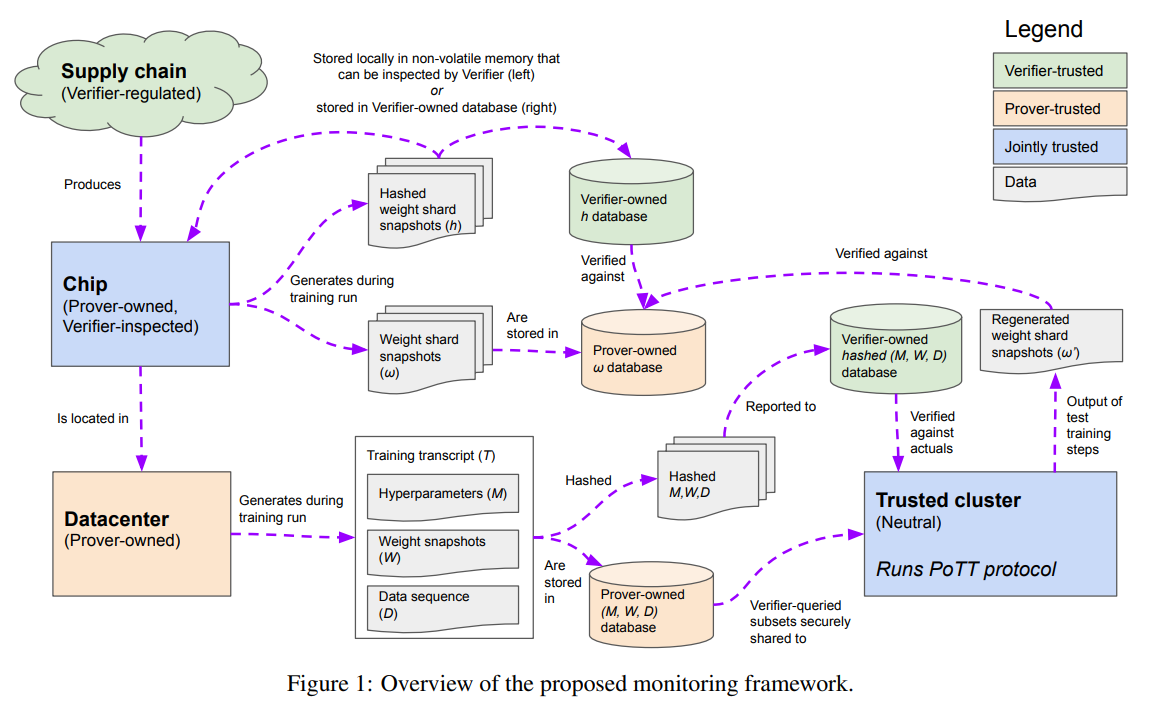
Fig 2: Overview of the proposed monitoring framework [1]
To ensure the integrity of the verification process, the framework introduces a "trusted cluster" – a set of chips that both the prover and the verifier trust. This cluster is designed to protect the prover's data from leaking while performing minimal ML inference and training required for the verification protocol. Regular controls on random samples of chips ensure ongoing compliance. Additionally, supply chain verification is implemented to track ML chips owned by each prover.
While the Chinchilla framework offers a comprehensive approach to monitoring ML training, it faces several challenges:
On-Chip Mechanisms: Enhancing Compute Governance [5]
On-chip mechanisms represent a promising and necessary approach to enforcing requirements and monitoring the use of compute. These built-in features offer several advantages for regulating AI development and usage.
On-chip mechanisms offer robust verification capabilities and product licensing features, enhancing the efficacy of compute governance. These embedded systems can validate claims made by the chip or its owner, enabling the verification of quantitative computations and datasets. This functionality ensures transparency and accountability in chip activities, providing a reliable means of oversight. Additionally, the implementation of product licensing, akin to software licenses, allows for precise control over chip usage based on compliance with regulatory requirements. This feature grants the potential to disable or limit chip functionality if regulations are not met, proving particularly useful in addressing issues such as smuggled chips or non-compliant owners.
Existing Implementations
Interestingly, many of the functionalities required are already in use across various technologies:
One fundamental challenge facing compute governance is the uncertainty surrounding future computing performance. While Moore's Law has historically driven exponential growth in computing power, enabling AI advancements through increased training compute scaling, this may not remain to be the case. If Moore's Law reaches its limits, advances in AI may start relying on different innovations, for example in algorithmic advancements, rather than just increasing compute. This would mean that compute is no longer the main driver of AI progress and therefore would reduce the importance of compute governance. Additionally, if the rate of chip developments slows down, so would the frequency of AI chip replacements, reducing the reach of existing governance strategies that monitor chip supply or implement new mechanisms on the latest hardware iterations.
As AI hardware continues to evolve, regulators face the complex task of identifying appropriate targets for oversight. The potential use of gaming GPUs for AI computational tasks traditionally reserved for specialised chips raises questions about which types of compute hardware should be subject to regulatory oversight, as indiscriminate targeting of all compute hardware could lead to privacy concerns and overly broad regulation.
It will be essential to monitor access to cloud compute as more people access compute in this manner. This may even be better for regulation and control as there is potential for more precise controls, control of the quantity actors can access, and flexibility to suspend access at any time.
As more countries develop their own semiconductor supply chains, international cooperation becomes imperative to establish cohesive regulatory frameworks that ensure global standards for security and ethical use of AI technologies.
Domain-specific AI applications may achieve dangerous capabilities in narrow fields with significantly reduced compute resources compared to general models. For general-purpose systems, compute serves as a fairly accurate proxy for capabilities, but specialised systems trained for potentially hazardous tasks could be achieved with far less compute. This shift challenges traditional metrics for evaluating compute requirements and calls for adaptive indices that align with specific application domains.
Furthermore, increased compute efficiency and hardware improvements could potentially enable hazardous systems to be trained on a wider range of devices, including consumer-grade hardware; and systems may become trainable on less powerful devices due to increased algorithmic efficiency. This may mean that compute loses its leverage as a leading approach for governance.
In conclusion, compute governance emerges as a critical component of AI regulation, leveraging the unique properties of hardware—detectability, excludability, and quantifiability—to effectively steer AI development. The concentrated nature of the compute supply chain further emphasizes its strategic importance. While frameworks like Yonadav Shavit's proposal offer promising approaches for monitoring and verifying AI development, they also highlight the need for continuous adaptation to technological advancements. The multifaceted challenges in this field, including uncertainties in computing performance, evolving hardware paradigms, and digital access to compute, necessitate proactive, adaptive, and collaborative regulatory strategies. By addressing these issues through international cooperation, stakeholders can foster an environment that promotes responsible innovation while ensuring AI safety.
Bibliography: